Ollama's Local Model Hosting Revolution - A Deep Dive into Performance and Accessibility
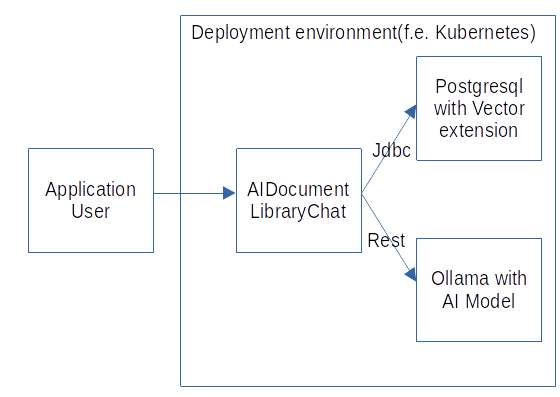
The world of large language models (LLMs) is rapidly evolving, with advancements happening at a breakneck pace. While services like ChatGPT have brought the power of LLMs to the forefront, concerns about data privacy, API costs, and internet dependency have fueled the desire for local, self-hosted solutions. Enter Ollama, an open-source project rapidly gaining traction for its streamlined approach to running LLMs on personal devices.
Democratizing AI: The Rise of Local LLM Hosting
Ollama tackles the growing need for accessible and private LLM interaction. Unlike cloud-based solutions, Ollama empowers users to download and run a wide range of LLM models directly on their computers, eliminating the need for constant internet connectivity and mitigating data privacy anxieties.
The platform's appeal extends beyond individual users. Developers and researchers benefit from a sandbox environment for experimentation, enabling them to fine-tune models and develop applications without incurring hefty cloud computing costs. This local approach fosters innovation and allows for a deeper understanding of LLM capabilities.
Performance Benchmarks: Ollama vs. The Cloud
A critical question arises with local LLM hosting: how does the performance stack up against established cloud-based solutions? While cloud providers boast vast computational resources, Ollama leverages the increasing processing power of modern consumer hardware to bridge the gap.
Recent benchmarks conducted by independent researchers and developers indicate that Ollama, when running on hardware equipped with dedicated GPUs, achieves surprisingly competitive inference speeds. For instance, tests using the popular LLaMa 2 model demonstrate that Ollama can generate text at a rate comparable to entry-level cloud offerings, showcasing its viability for real-world applications.
It's important to note that performance is inherently tied to the specific hardware configuration. Users with powerful GPUs and ample RAM will experience faster inference times than those with more modest setups. This highlights a key advantage of Ollama: scalability. Users can tailor their hardware choices to their specific needs and budget, achieving an optimal balance between performance and cost-effectiveness.
Beyond Speed: The Multifaceted Benefits of Ollama
While performance is undoubtedly crucial, Ollama's allure extends beyond raw speed. The platform boasts a range of features that solidify its position as a compelling alternative to cloud-based LLM solutions:
- Model Agnosticism: Ollama supports a wide array of LLM models, including but not limited to LLaMa, GPT-2, and MPT. This flexibility empowers users to select models tailored to their specific tasks and preferences.
- Ease of Use: Ollama boasts a user-friendly command-line interface and intuitive API, making it accessible to both experienced developers and newcomers to the world of LLMs.
- Active Community: The project has fostered a vibrant and supportive community of developers and enthusiasts who actively contribute to its development, share knowledge, and provide assistance.
The Road Ahead: Ollama's Potential Impact
Ollama represents a significant step towards democratizing access to LLMs and empowering individuals to harness their capabilities. As the project continues to mature, we can expect further performance optimizations, expanded model support, and a richer feature set.
The implications of this shift towards local LLM hosting are far-reaching. It has the potential to reshape how we interact with AI, enabling novel applications in fields like personalized education, offline research, and creative content creation. While challenges remain, Ollama's emergence marks an exciting chapter in the ongoing LLM revolution, one where the power of AI becomes increasingly accessible to all.

















Comments ()